index
大模型和人类的思想并不相同,它的思考本质上是文字接龙是概率模型,通过推理当前文字后面大概率出现的文字来回答问题
大模型应用场景:
- 自然语言处理NLP(Natural Language Processing):其中包含自然语言理解(Natural Language Understanding)和自然语言生成(Natural Language Generation)
- 语音处理(SLP)
- 图像视频处理
机器学习
- 有监督学习:使用标记数据进行训练,目标是预测或分类。常用于分类、回归和目标检测等任务。
- 无监督学习:使用未标记数据进行训练,目标是发现数据中的结构和模式。常用于聚类、降维和异常检测等任务。
- 强化学习:机器在与环境交互的过程中,通过试错来学习如何采取行动,以获得最大的奖励。其核心在于智能体根据当前状态选择动作,并根据环境反馈的奖励来调整策略。
机器学习效果评估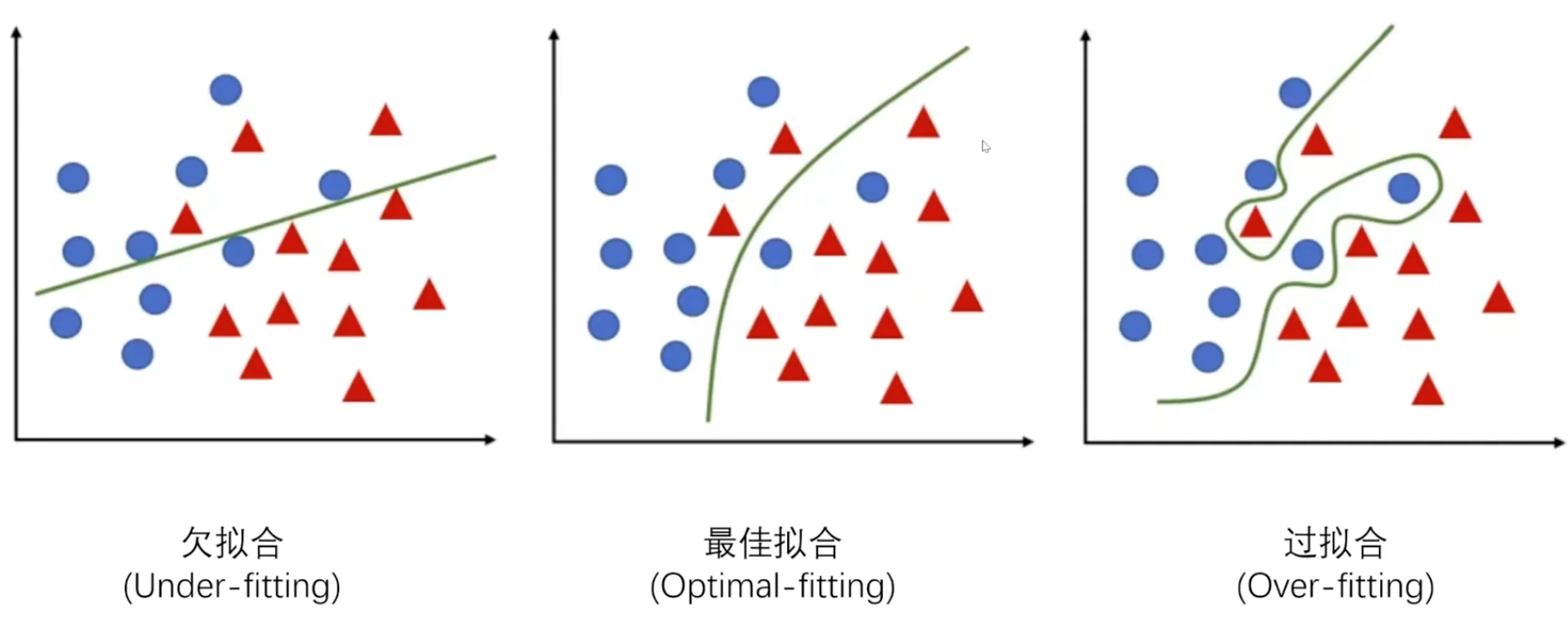
- 欠拟合:当模型过于简单,无法捕捉训练数据中的关键特征或复杂关系时,就发生了欠拟合。
- 最佳拟合:当模型在训练集上学得不错,并在测试集上也有良好表现时,说明模型“理解”了数据的主要模式,称为正常拟合或良好泛化。
- 过拟合:当模型过于复杂,把训练集的“细节+噪声”全部记住后,在新数据上表现就很差,这就是过拟合。
深度学习
一种机器学习架构,使用多层人工神经网络,模仿人脑的工作方式来解决复杂的模式识别问题。能够从图像,语音,自然语言中自动提取高层次的特征。
提示词工程
ai回答的准确与否并不很大程度上取决于模型的能力,而是很大程度上取决于前面的信息准确与否
注
提示工程(Prompt Engineering)是一项通过优化提示词(Prompt)和生成策略,从而获得更好的模型返回结果的工程技术。
好的提示词需要不断调优,其中要具体描述清楚自己想要什么,并告诉ai细节,不能让ai去猜测
提示词通常包括以下内容:
- 指示(lnstruction):描述要让它做什么?
- 上下文(Context):给出与任务相关的背景信息
- 例子(Examples):给出一些例子,让模型知道怎么回复
- 输入(lnput):任务的输入信息
- 输出(OutputFormat):输出的格式,想要什么形式的输出? 示例:
instruction = "根据下面的上下文回答问题。保持答案简短且准确"
context= "Teplizumab起源于一个位于新泽西的药品公司"
query="OKT3最初是从什么来源提取的?"
# 封装提示词
prompt = f"""{instruction} ### 上下文{context} ### 问题:{query}"""RAG
检索增强生成(Retrieval Augmented Generation)技术是一种结合信息检索与生成模型的新型架构,其核心思想是利用外部知识库或文档集合为大模型提供实时、准确的背景信息,从而弥补大模型的局限性。
为什么需要RAG: 大模型的知识完全来自训练数据,存在以下局限:
- 知识过时:无法知道训练数据之后的事件
- 幻觉问题:编造看似合理但错误的信息
- 缺乏特定领域知识:如公司内部文档、专业数据库
普通的检索(关键字检索)如红线所示:用户的查询直接发送给大模型,大模型直接给出回答 rag(向量检索:方向一致)的回答:用户给出的查询先发送给检索者,检索者拿到问题后会在知识库检索与用户查询相关的文档,并将用户的查询和检索出的文档一并发送给大模型,大模型根据这些数据以及自己已有的信息给出回答 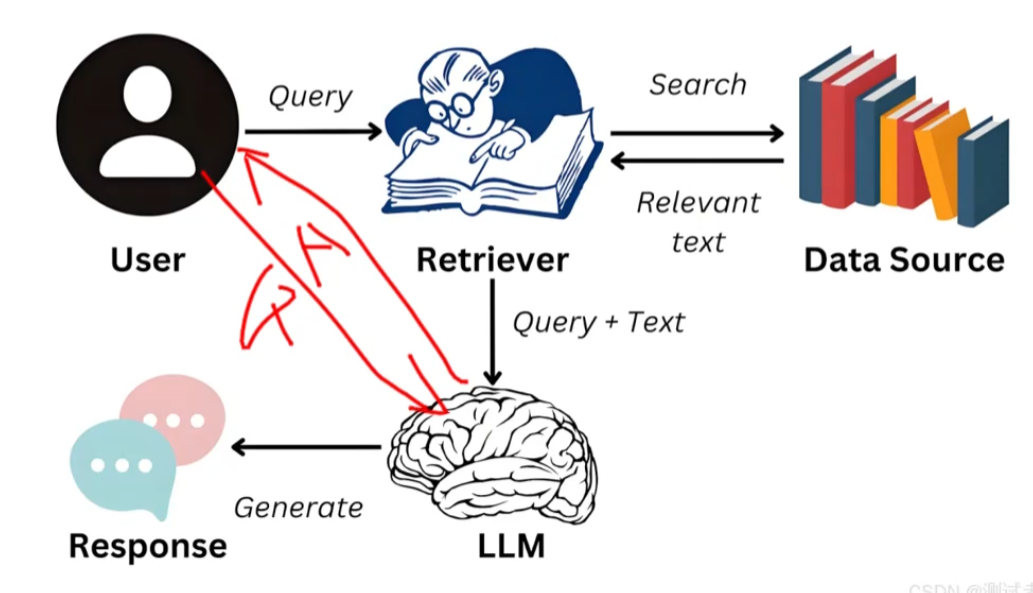
RAG由两部分组成:
- 检索模块:在知识库中检索与当前输入问题相关的文档或片段。
- 生成模块:基于检索结果和原始输入,通过大模型生成准确、丰富的回答。
检索方案
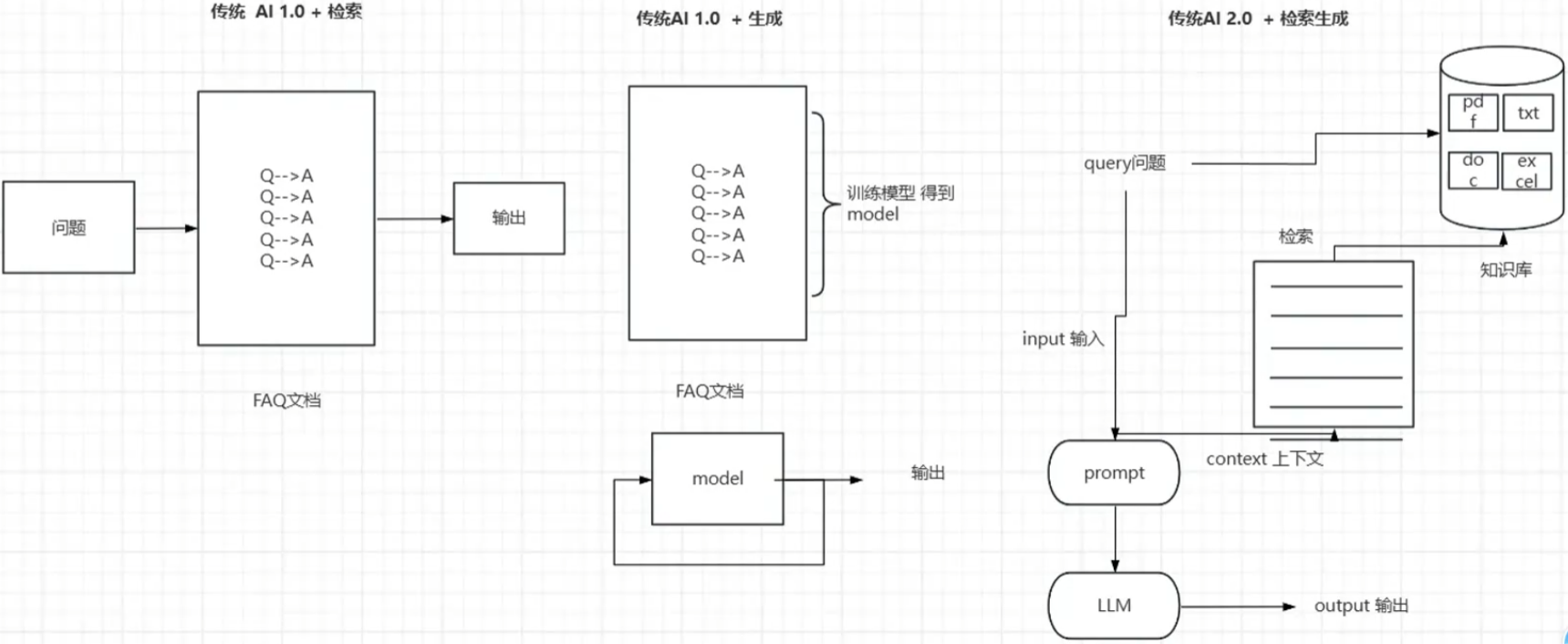
- 关键字检索:只能对特定的已经存在的问题进行检索,不存在的问题解答不了
- 生成模式:将已有的知识喂给ai,模型总结并微调,这种方法需要一定的成本(训练模型),并且准确性也无法保证,通常需要人工协作(将问题给到客服,客服去模型中查问题,拿到回答后再经过一定的修饰回答给客户)
- rag:知识库中的数据进行分词处理、向量化(将同一类型的问题归一到同一向量)、筛选、清洗等整理后进行rag检索
文档分割
文档分割是为了更好的构建知识库,一个文档中通常会只有很少一部分是与用户提出的问题相关的,而大部分可能涉及多种方向,对文档进行切割可以将知识进行分类,增加相关度
有多种方式:
- 根据句子分割:句子段落,一个句子一个chunk
- 按照字符数切分:设置固定的字符数,缺点不连贯
- 按照固定字符:设置固定的字符,结合一定的重复字符
- 递归方法:设置固定的字符,结合一定的重复字符,在加对应的语义
- 根据语义进行分割:语义
向量相似度计算: 余弦距离Cosine:基于两个向量夹角的余弦值来衡量相似度。 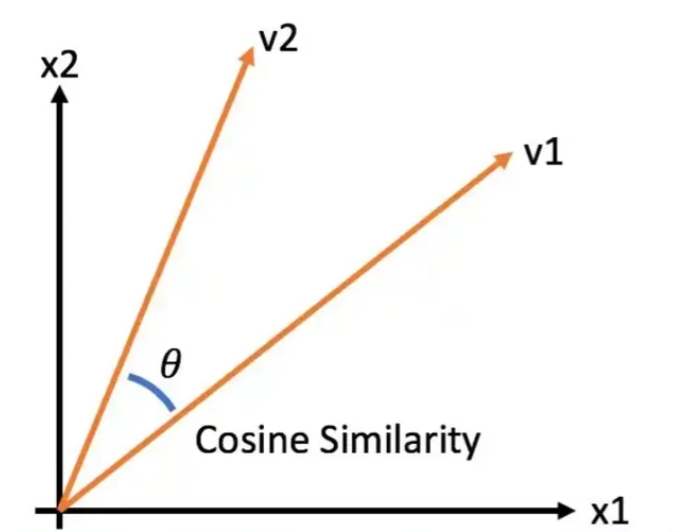
向量数据库
向量数据库(VectorDatabase),也叫矢量数据库,主要用来存储和处理向量数据。
检索方法:
- 单独比较
- index
- ApproximateSearch(近似搜索),更准确地说是 Approximate Nearest Neighbor Search(ANNS,近似最近邻搜索) LSH局部敏感哈希 LVF(倒排文档)+PQ(乘积量化) HNSW DiskANN
搜索算法
- 倒排索引
- KNN
- ANN
- PQ
AI Agent
AI Agent(人工智能代理)是一种能够自主感知环境、进行思考、做出决策并执行任务的智能软件,与传统聊天机器人不同,AIAgent的系统核心在于具备“代理权”(Agency),能够主动地“做事”,而不仅仅是“回答问题”。 代理的是一个流程 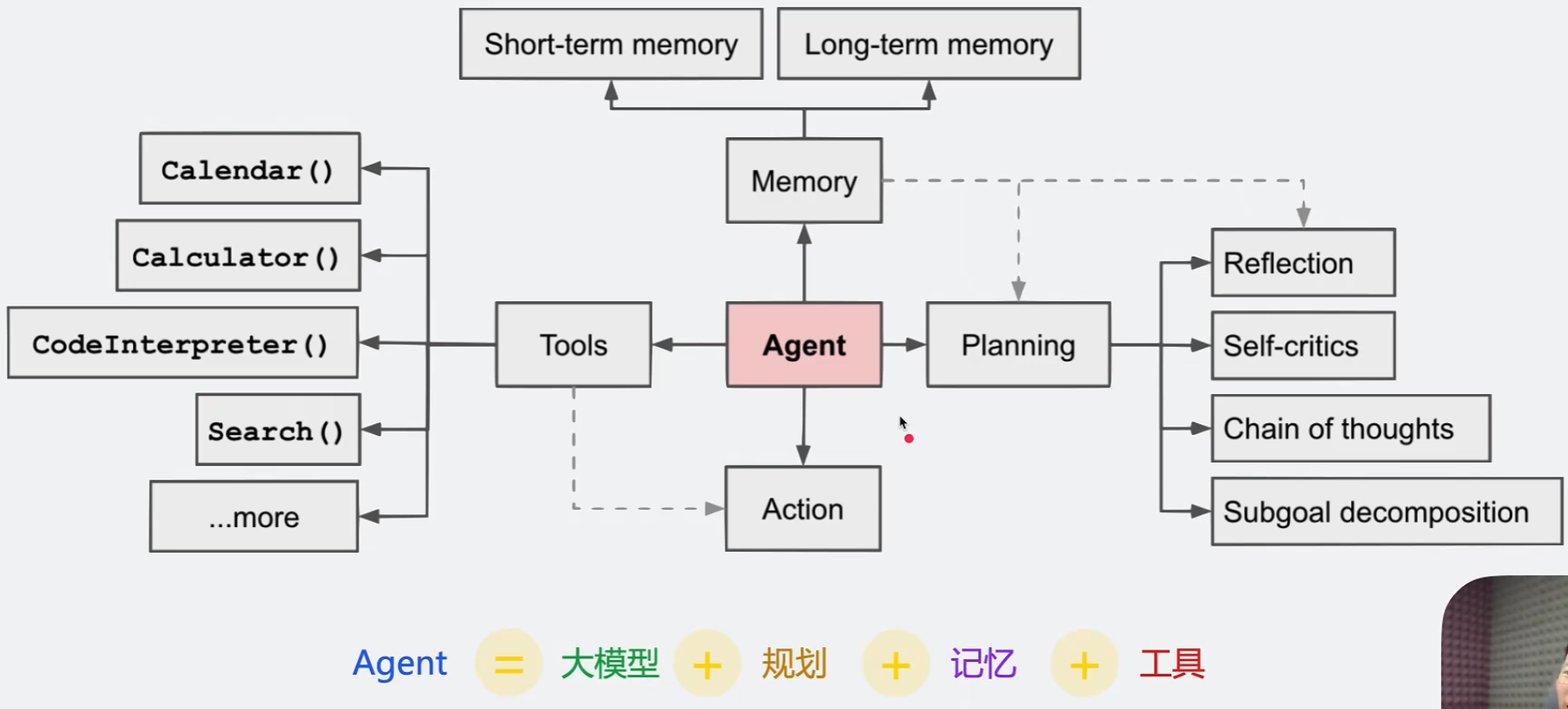
- 规划(Planning):智能体会把大型任务分解为子任务,并规划执行任务的流程;智能体会对任务执行的过程进行思考和反思,从而决定是继续执行任务,或判断任务完结并终止运行。
- 记忆(Memory):短期记忆,是指在执行任务的过程中的上下文,会在子任务的执行过程产生和暂存,在任务完结后被清空。长期记忆是长时间保留的信息,一般是指外部知识库,通常用向量数据库来存储和检索。
- 工具使用(Tools):为智能体配备工具API,比如:计算器、搜索工具、代码执行器、数据库查询工具等。有了这些工具API,智能体就可以是物理世界交互,解决实际的问题。
- 执行(Action):根据规划和记忆来实施具体行动,这可能会涉及到与外部世界的互动或通过工具来完成任务。
记忆
- 形成记忆:大模型在大量包含世界知识的数据集上进行预训练。在预训练中,大模型通过调整神经元的权重来学习理解和生成人类语言,这可以被视为“记忆“的形成过程。通过使用深度学习和梯度下降等技术,大模型可以不断提高基于预测或生产文本的能力,进而形成世界记忆或长期记忆
- 短期记忆:在当前任务执行过程中所产生的信息,比如某个工具或某个子任务执行的结果,会写入短期记忆中。记忆在当前任务过程中产生和暂存,在任务完结后被清空。
- 长期记忆:长期记忆是长时间保留的信息。一般是指外部知识库,通常用向量数据库来存储和检索。
多智能体协同模式
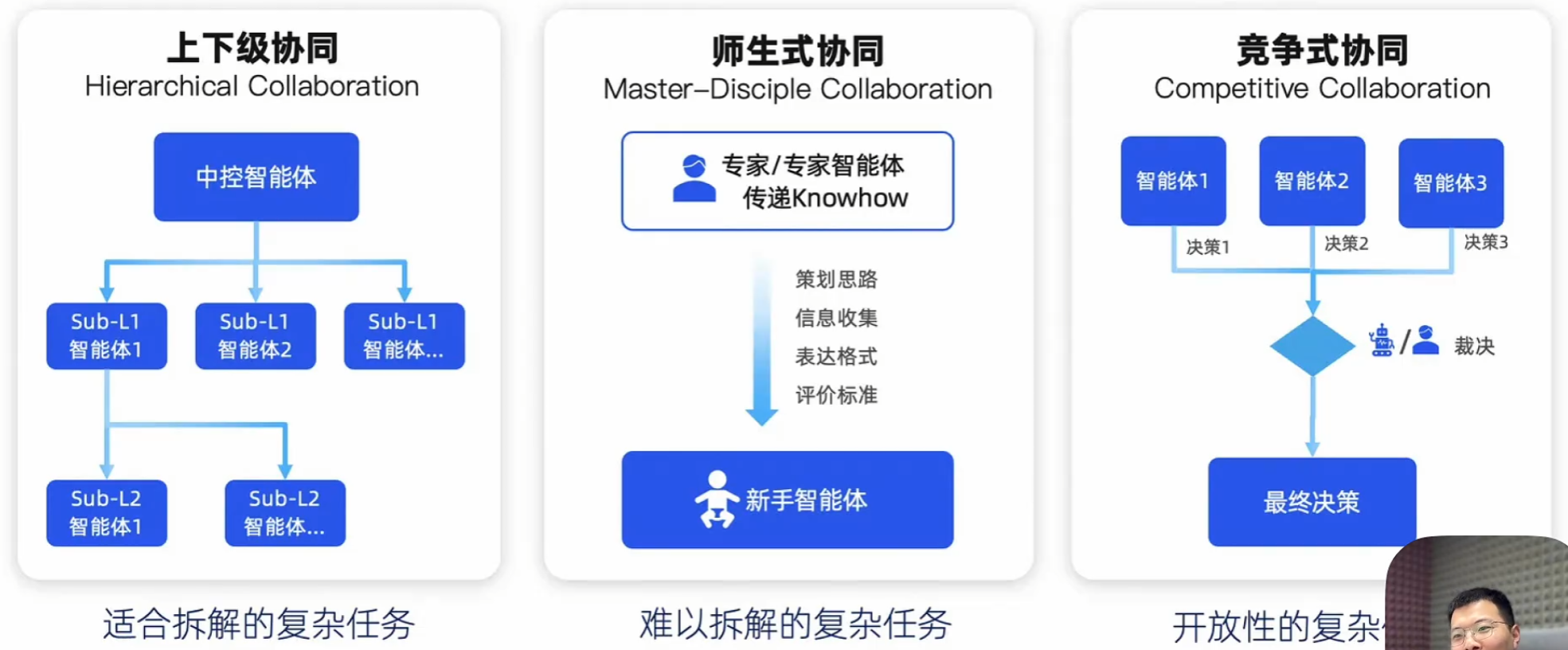
- 上下级:将一个复杂任务拆分成不同模块,不同的智能体完成不同的模块,模块还可以再拆分
- 师生式:由一个专家智能体完成复杂的任务,并将结果交给学生智能体做简单的处理,如精简回答等
- 竞争式:不同智能体给出不同的方案,由用户抉择使用哪种方案
贡献者
 PinkDopeyBug
PinkDopeyBug版权所有
版权归属: